Let’s see if I can finish out these last few problems.
The problem: Fault Detection in Directed Graphs. This is problem MS18 in the appendix
The description: Given a directed, acyclic graph G=(V,A). We denote the set I as the set of vertices with indegree 0, and the set O as the set of vertices of outdegree 0. Given an integer K, can we find a set of K or less paths starting at a vertex in I, and ending at a vertex in O, where every vertex in V is on at least one of those paths?
Example: It took me a long time to wrap my head around this, and I’m still not 100% convinced the version in the paper is this problem. But here is an example that I think is helpful:
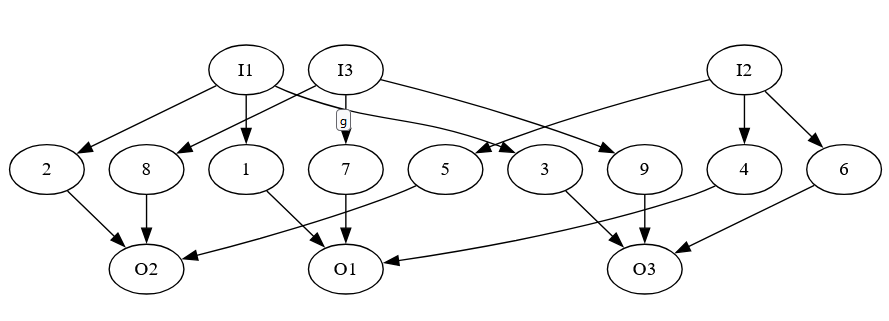
Notice that each of the middle vertices is on a separate path from an I vertex to an O vertex. So, we will need all 9 combinations (from every I vertex to every O vertex) to ensure that all middle vertices are covered.
But now, suppose we add one more edge from 9 to O2:
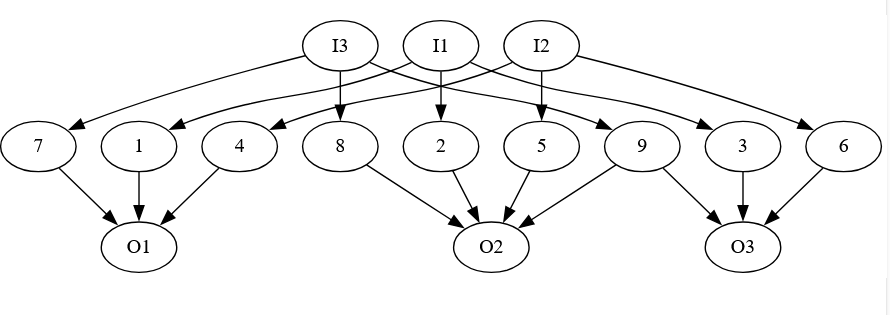
Now we don’t need a separate start and end from I3 to O3, since there is a path from I3 to 02, choosing that pair as a start/end combination will give us paths that cover both vertex 8 and vertex 9.
Reduction: The paper by Ibaraki, Kameda, and Toida write the problem a bit differently, and they have a lot of different problems in their paper, and to be honest, I’m not sure which one is for this problem. (I think it’s P3? But their reduction seems to have extra stuff that we don’t need).
So, I’m going to try to do the reduction myself from X3C, like G&J suggest in the appendix, but take inspiration for how the structure is built from the paper.
To do this, I really want a version of this problem where we only care about paths through internal nodes (vertices not in I or O). So, it’s possible that a vertex in I or O is not in a path, but every vertex not in I or O is in some path. We can reduce this to the real version by creating extra “dummy” vertices that are internal: For each vertex ij ∈ I, create a vertex aj, and an edge ij → aj, and replace all other edges exiting ij with corresponding edges leaving aj instead. We can do the same thing with O by placing vertices “before” the O vertices. That way the only way to have a path through those new internal vertices is to have a path through all I and O vertices as well.
For our real reduction, we start with an X3C instance- a set of elements X (|X| = 3q, for some positive q), and a collection C of 3-element subsets of X. Both our I set and our O set will have one vertex for each element of C (so 2 copies of all elements total). In between, we will create a set of vertices X, one vertex for each element of X. We will have edges from each I vertex (a subset) to the 3 X (element) vertices it is a part of, and from each X vertex to the O vertices it is a part of. Set K’ = K.
If we have an X3C instance, then choosing the sets in the solution as the I and O elements, and making them pairs, will give us a cover of all of the X elements in the middle.
If we have a cover of size K, then if we have the same sets in both the I and the O sets (so both “sides” agree on what sets to use), we clearly have an X3C solution. It’s possible, though, that there is some pair (Ia, Ob) where a != b. However, we know that:
- Each element in X is along some path from an I vertex to an O vertex
- We need K pairs of elements to make the cover, and we have 3K elements to cover.overall, and so each element in X is a member of exactly one path from an I vertex to an O vertex.
- So, each element in X occurs in exactly one I vertex in some pair in the solution. (And, each I vertex occurs at most once in some pair)
- Thus, just taking all of the sets corresponding to the I vertices gives us an X3C solution
- (And, relatedly, we can shift the O vertices to be the corresponding sets to the I vertices and remain a cover of the internal vertices).
Difficulty: 7. I’m still not entirely sure I am talking about the right problem from the paper. It also took me a lot of time to come up with the reduction, because X3C wants us to choose some, but not all, of the sets in the collection, but the whole point of this problem is that we can leave things out. I played with an idea where all of the vertices connected to each other 3 times, but couldn’t make it work. Hopefully this version makes more sense.
 ?
? T*?
T*?