This is it! The end of the appendix!
The problem: Fault Detection with Test Points. This is problem MS19 in the appendix.
The description: Given a directed acyclic graph G=(V,A) with one “source” vertex s with indegree 0, and one “destination” vertex t with outdegree 0, and an integer K, can we find a subset A’ of A of size K or less that induces a “test set” T:
T = 
Where T has the property that for all pairs of vertices  , there is some pair
, there is some pair  such that
such that  is on a path from
is on a path from  to
to  , but there is no path from to containing w.
, but there is no path from to containing w.
What that description means: Can I mark K or less edges so that we can use marked edges to “test” all pairs of vertices? We “test” a pair of vertices by sending an electric signal along a path between those edges. If a test fails (or passes), we know that something along that path has failed (or passed). We want to be able to distinguish 2 vertices v and w by seeing if there is a test that includes v but not w (or vice versa) so that if that test fails, we can tell whether the problem is v or w, and eliminate the other possibility.
Example: It’s a little weird to create an example, because you are marking edges, and you need a path between vertices that touch marked edges. But that path is allowed to be a single edge. Suppose we have:
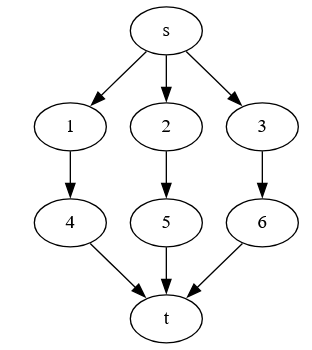
Suppose we put test points on all edges going from s, and all edges entering t. Then we can distinguish points using these edges. For example:
- 1 and 2 are distinguished using the s->1 edge as a path. (The path from s->1 includes 1 but not 2)
- 1 and 5 are distinguished using the s->2->5->t path (the s->2 and 5->t edges).
- 3 and 6 are distinguished using the s->3 edge as a path.
Reduction: I think this is P1 from the paper by Ibaraki, Kameda, and Toida. They reduce from Minimum Test Set, (called “Set Distinguishibility” in the paper which is very close to what we need.
So we are given a set S of elements, and a collection C of subsets of elements. We then build a graph. Here it is from the paper:
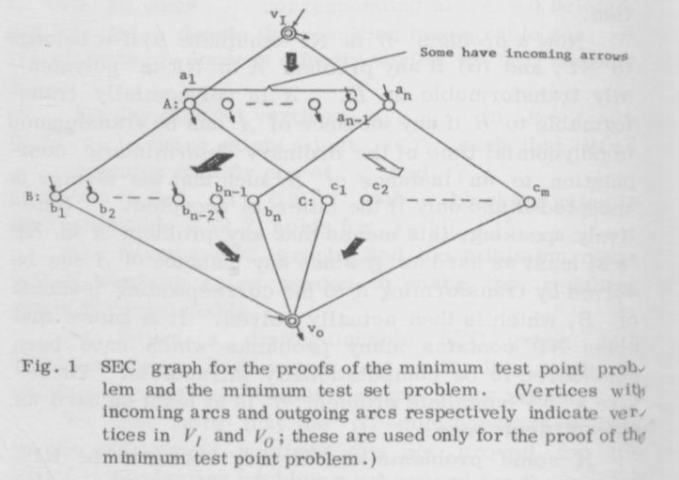
A and B hold one vertex for each set in C. C has one vertex for each element in S. The big dark arrows mean that all possible connections between those sets exist. The big white arrow means that there is an edge from ai to cj if element j is in set i.
We will need a way to distinguish all C vertices, and can do that by placing test points on some of the edges between VI and the A vertices. (We will be placing them on the edges that connect to vertices that will be the sets that solve the Minimum Test Set problem).
We also need to distinguish the elements of B from each other. We’ll need new test points for that, and we can place them on the edges between the A and B vertices.
The little arrows in the picture show which edges we are putting in the test set, going into and coming out of the vertices.
Difficulty: 8 Like the last problem, I’m not sure if this is the right problem. I also wonder why we need the B vertices at all- they don’t seem necessary for us to connect the C vertices and solve the Test Set problem. Maybe I’m missing something?
 ‘
‘