This is a cool, fun reduction. I also teach And/Or graphs in my Artificial Intelligence class, so it was fun to see this as a problem here.
The problem: Minimum Weight And/Or Graph Solution. This is problem MS16 in the appendix.
Description: An And/Or graph is a directed, acyclic graph, where each vertex is marked as either an “and” node, or an “or” node. We’re given a start vertex, s. Then we “solve” the subtree at s by:
- Solving all children of s, if s is an “and” node,
- Or, solving one child of s, if s is an “or” node.
The solution proceeds recursively, until we get to a leaf, which can be solved directly. Here is an example from the paper:
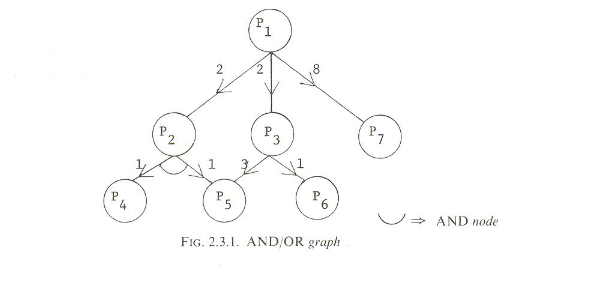
So, to solve P1, we could solve either P2, P3, or P7. To solve P2, we’d need to solve both P4 and P5.
In this problem, the edges are weighted, and we’re asked: Given an integer K, is there a solution that traverses edges costing K or less?
Example: In the graph above, the cheapest solution costs 3: Solve P1 by solving P3, solve P3 by solving P6. If P3 was an “and” node, instead of an “or” node, then the best solution would cost 4: Solve P1 by solving P2, solve P2 by solving both P4 and P5.
Reduction: Sahni’s paper has a bunch of reductions we’ve done. This time, he uses 3SAT. So, from a given 3SAT instance, we build a graph:
- S is the root node, and is an “and” node
- S has one child for each variable (x1..xn). There is also one extra child, P.
- Each xi is an “or” node with 2 children, one for “true”, one for “false”. (So 2n children total)
- Each of these 2n nodes have 1 edge coming out of it to one of the 2n leaves of the tree.
- P is an “and” node, and has one child for each clause (C1..Ck).
- Each clause node is an “or” node, and has 3 edges corresponding to its literals. So if variable xi appears in clause Cj positively, there is an edge to the “true” child of xi. If the negation ~xi appears, there is an edge to the “false” child of xi.
- The weights of each edge are 0, except for the 1-degree edges going to the leaves, which cost 1.
To solve this graph, we need to solve S, which means we need to solve each variable (by “choosing” a truth setting for it), and we also need to solve P. Solving P means we need to solve each clause. Each clause is solved by choosing a truth setting for one of its literals that makes the clause true. Since we are already choosing a truth setting for each variable, we are paying N in cost. If we can choose setting of the variables that also solve each clause, we pay no more than N in cost, and also satisfy each clause. If the formula is unsatisfiable, then we need to solve one variable “twice” by setting it to true and false, making us pay more than N overall.
So the formula is satisfiable if and only if the tree cost is exactly N.
Difficulty: 6. I don’t know that I’d expect a student to come up with this themselves. It is similar to a lot of the 3SAT reductions we’ve done, though (one “thing” per clause, one “thing” for each variable setting, connections between the clause and the settings of its literals), so if a few of these were gone over with students, maybe this could be presented along with them.
![f(n) = \min_{1 \leq i \leq 3} [f(n-i) + f(i) + n]](https://npcomplete.owu.edu/wp-content/ql-cache/quicklatex.com-1d07499d4b6340ae921574e9f3f3ad12_l3.png "Rendered by QuickLaTeX.com") if
if 

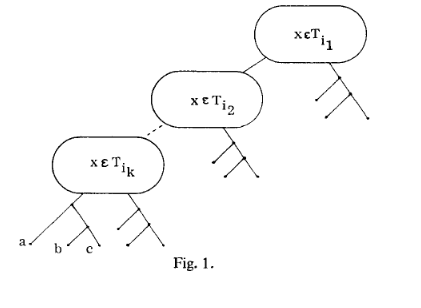
 sets have to form a cover. This means we get the minimum height (of K) from the tree if and only if we have a cover from C.
sets have to form a cover. This means we get the minimum height (of K) from the tree if and only if we have a cover from C.